Yuekai Sun
Research
My research leverages statistical science to improve the reliability and safety of AI in the real world. Towards this goal, we work on:
AI evaluation
Despite transformative advances in generative AI, we evaluate GenAI in the same ways as we evaluate simpler predictive models (ie accuracy on held-out examples). Such simple evaluation protocols cannot assess the rich outputs holistically, leading to blind spots that ultimately hamper AI safety and reliability. To fill this gap between AI evaluation needs and practice, we develop new statistical theory and methods for AI evaluation. Some representative papers are:
- Large Language Model Routing with Benchmark Datasets
T Shnitzer, A Ou, M Silva, K Soule, Y Sun, J Solomon, N Thompson, M Yurochkin. COLM 2024. - tinyBenchmarks: evaluating LLMs with few examples
F Maia Polo, L Weber, L Choshen, Y Sun, G Xu, M Yurochkin. ICML 2024. - Fusing Models with Complementary Expertise
H Wang, F Maia Polo, Y Sun, S Kundu, E Xing, M Yurochkin. ICLR 2024.
Algorithmic fairness
We take a statistical approach to algorithmic fairness: algorithmic biases are often caused by distribution shifts (eg due to sampling biases in the training data), which suggests they are statistical problems that admit statistical solutions. A key insight from our work is (contrary to popular belief) aligning AI so that they are fair/safe/transparent may not be at odds with accuracy. In fact, alignment can improve (out-of-distribution) performance. We can even exploit the distribution shifts to achieve otherwise unachievable fairness objectives (eg achieve equality of outcomes with (policies that satisfy) equality of opportunity/treatment). This statistical approach to fairness also motivates some of our more fundamental work on transfer learning. Here are some representative papers:
- Algorithmic Fairness in Performative Policy Learning: Escaping the Impossibility of Group Fairness
S Somerstep, Y Ritov, Y Sun. FAccT 2024. - Domain Adaptation meets Individual Fairness. And they get along.
D Mukherjee, F Petersen, M Yurochkin, Y Sun. NeurIPS 2022. - SenSeI: Sensitive Set Invariance for Enforcing Individual Fairness
M Yurochkin, Y Sun. ICLR 2021.
Training LLMs
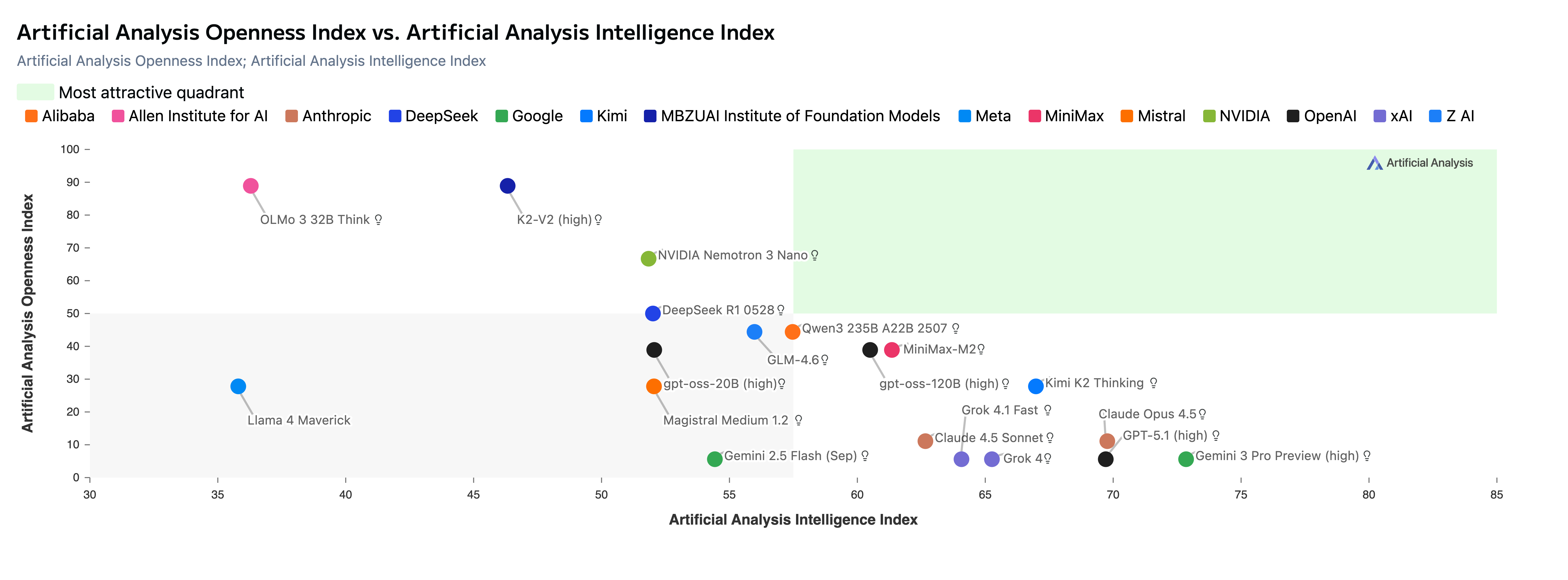
Open-weight models such as DeepSeek V3/R1 hide the two most critical factors affecting model behavior: the training algorithm and data. This hinders assessment of the models’ capabilities and defects (eg trace capabilities/defects to documents in the training data) and stifles innovation at the pre-training and mid-training stages. To address the lack of fully open (open weights, training algorithm, and training data) LLMs, we train the K2-series of models. The latest in the series, K2-V2, is state-of-the-art among fully open LLMs (outperfoming Olmo 3.1-Think 32B) and LLMs in its size-class (outperforming LLaMA 3.3-70B and Qwen2.5-72B).
Transfer learning
AI often encounter adversarial and out-of-distribution inputs in the real world, but the pernicious effects of distribution shifts are poorly understood. This is a form of technical debt that hinders us from anticipating AI risks before they arise. We seek to repay this technical debt. Some representative papers are:
- A transfer learning framework for weak-to-strong generalization
S Somerstep, F Maia Polo, M Banerjee, Y Ritov, M Yurochkin, Y Sun. ICLR 2025. - An Investigation of Representation and Allocation Harms in Contrastive Learning
S Maity, M Agarwal, M Yurochkin, Y Sun. ICLR 2024. - Understanding new tasks through the lens of training data via exponential tilting
S Maity, M Yurochkin, M Banerjee, Y Sun. ICLR 2023.